Last Updated on July 3, 2013 by nghiaho12
Spent like the last 2 weeks trying to find a bug in the code that prevented it from learning. Somehow it miraculously works now but I haven’t been able to figure out why. First thing I did immediately was commit it to my private git in case I messed it up again. I’ve also ordered a new laptop to replace my non-gracefully aging Asus laptop with a Clevo/Sager, which sports a GTX 765M. Never tried this brand before, crossing my fingers I won’t have any problems within 2 years of purchase, unlike every other laptop I’ve had …
I’ve gotten better results now by using a slightly different architecture than before. But what improved performance noticeably was increasing the training samples by generating mirrored versions, effectively doubling the size. Here’s the architecture I used
Layer 1 – 5×5 convolution, Rectified Linear units, 32 output channels
Layer 2 – Average pool, 2×2
Layer 3 – 5×5 convolution, Rectified Linear units, 32 output channels
Layer 4 – Average pool, 2×2
Layer 5 – 4×4 convolution, Rectified Linear units, 64 output channels
Layer 6 – Average pool, 2×2
Layer 7 – Hidden layer, Rectified Linear units, 64 output neurons
Layer 8 – Hidden layer, Linear units, 10 output neurons
Layer 9 – Softmax
The training parameters changed a bit as well:
- learning rate = 0.01, changed to 0.001 at epoch 28
- momentum = 0.9
- mini batch size = 64
- all weights initialised using a Gaussian of u=0 and stdev=0.1
For some reason my network is very sensitive to the weights initialised. If I use a stdev=0.01, the network simply does not learn at all, constant error of 90% (basically random chance). My first guess is maybe something to do with 32bit floating point precision, particularly when small numbers keep getting multiply with other smaller numbers as they pass through each layer.
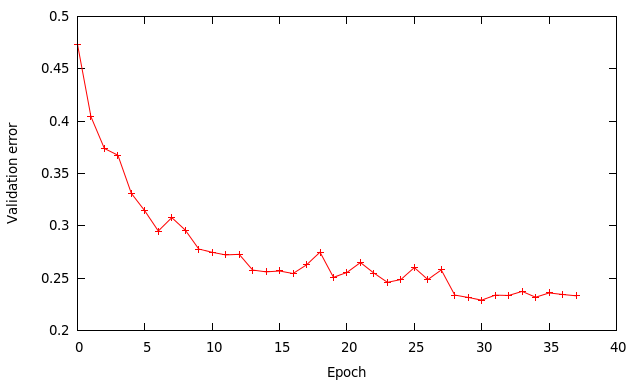 The higher learning rate of 0.01 works quite well and speeds up the learning process compared to using a rate of 0.001 I used previously. Using a batch size of 64 instead of 128 means I perform twice as many updates per epoch, which should be a good thing. A mini batch of 128 in theory should give a smoother gradient than 64 but since we’re doing twice as many updates it sort of compensates.
The higher learning rate of 0.01 works quite well and speeds up the learning process compared to using a rate of 0.001 I used previously. Using a batch size of 64 instead of 128 means I perform twice as many updates per epoch, which should be a good thing. A mini batch of 128 in theory should give a smoother gradient than 64 but since we’re doing twice as many updates it sort of compensates.
At epoch 28 I reduce the learning rate to 0.001 to get a bit more improvement. The final results are:
- training error – 9%
- validation error – 23.3%
- testing error – 24.4%
The results are similar to the ones by cuda-convnet for that kind of architecture. The training error being much lower than the other values indicates the network has enough capacity to model most of the data, but is limited by how well it generalises to unseen data.
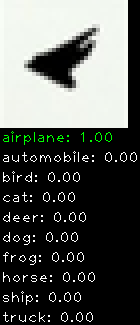
Numbers alone are a bit boring to look at so I thought it’d be cool to see visually how the classifier performs. I’ve made it output 20 correct/incorrect classifications on the test datase4t with the probability of it belonging to a particular category (10 total).
Correctly classified
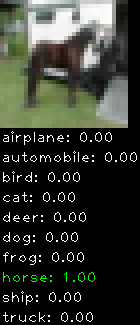
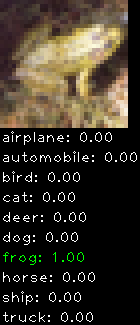
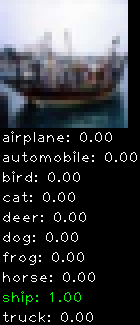
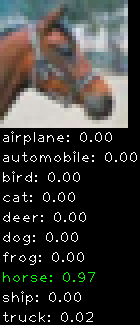
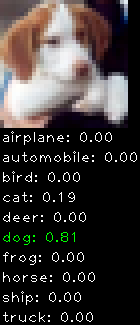
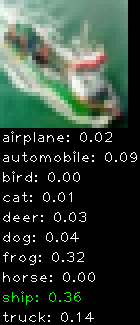
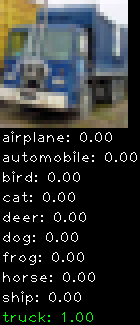
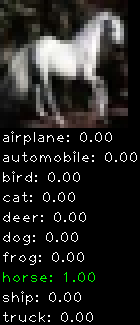
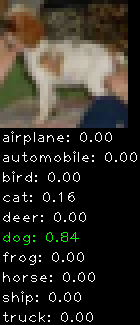
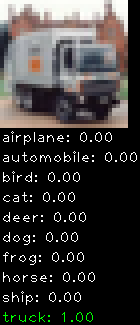
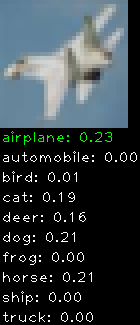
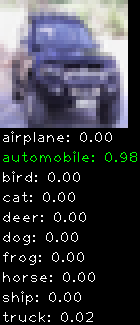
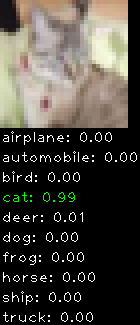
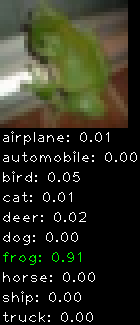
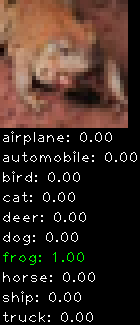
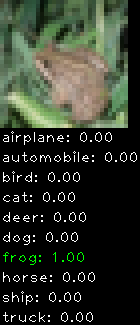
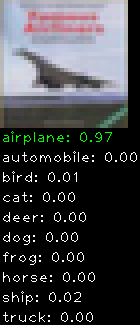
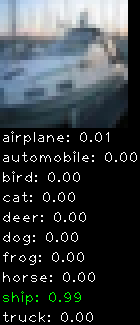
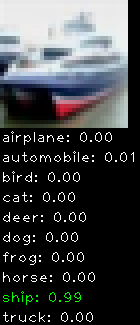
Incorrectly classified
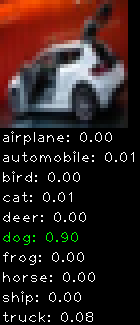
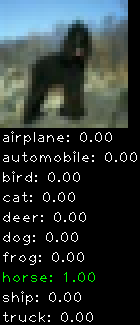
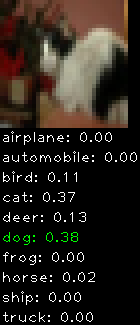
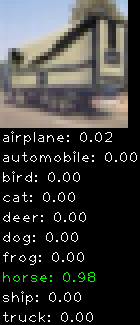
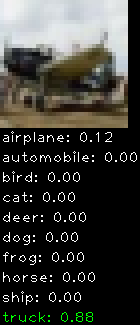
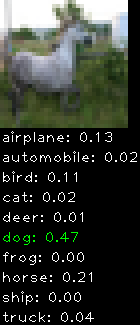
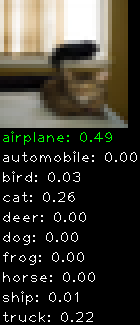
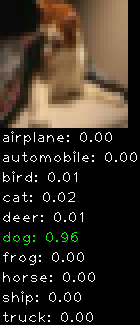
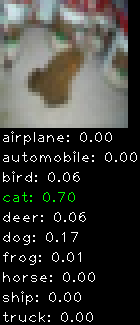
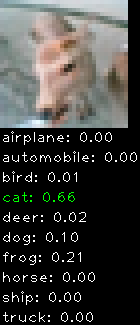
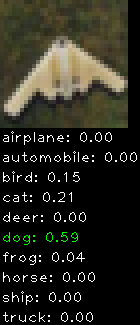
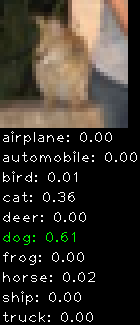
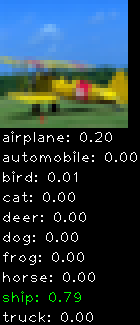
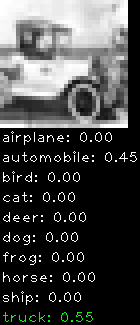
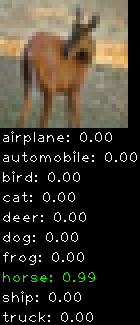
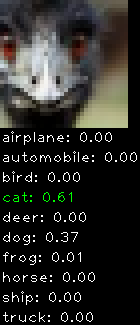
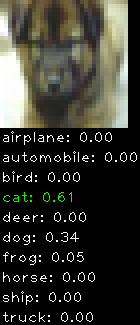
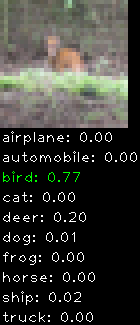
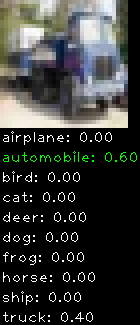
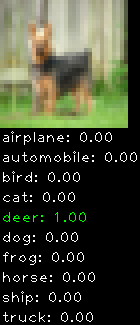
The miss classification are interesting because it gives us some idea what trips up the neural network. For example, the animals tend to get mix up a bit because they share similar physical characteristics eg. eyes, legs, body.
Next thing I’ll try is to add translated versions of the training data. This is done by cropping the original 32×32 image into say 9 overlapping 24×24 images, evenly sampled. For each of the cropped images we can mirror them as well. This improves robustness to translation and has been reported to give a big boost in classification accuracy. It’ll expand the training data up to 18 times (9 images, plus mirror) ! Going to take a while to run …
I’m also in the process of cleaning the code. Not sure on a release date, if ever. There are probably better implementation of convolutional neural network (EBlearn, cuda-convnet) out there but if you’re really keen to use my code leave a comment below.
Nghia Ho,
What references are you using to implement the convolutional neural network? The references I have (besides the original work from LeCun in late 90’s) are more focused on the “self-taught” learning that is very popular at the moment (RBMs, autoencoders), and don’t explain in much detail the convolutional training.
Thanks
Hi,
I don’t have any particular reference but LeCun ones are pretty good. I found this one gave a good overview, “Convolutional Networks and Applications in Vision”, and only 4 pages too. I mostly relied on my existing knowledge of standard neural network and backpropgation algorithm (from Geoff Hinton’s Coursera course). It took me a while to get my head around the maths for the convolution layer. I also asked some questions on metaoptimize.com, which cleared some ambiguity.
Awesome work man. I am a grad student at Georgia Tech and was interested to experiment, would you be able to share your code? Thanks.
I’ll try and do it this weekend after cleaning up more of the code. Out of curiosity have you tried any other implementation on the net?
Hello Mano,
did you compile the code on osx? Im currently working on a version for osx. I also want to improve some parts of the code…
Gerald
I will like to study your code sir. I’m new in this area . I have reading paper but I want to go into the practical aspect to undestand convolutional neural net better. Pls I need step by step
Take the Coursera course on Neural Networks, that’s how I got the background.