Last Updated on June 29, 2013 by nghiaho12
I’ve been experimenting with convolutional neural networks (CNN) for the past few months or so on the CIFAR-10 dataset (object recognition). CNN have been around since the 90s but seem to be getting more attention ever since ‘deep learning’ became a hot new buzzword.
Most of my time was spent learning the architecture and writing my own code so I could understand them better. My first attempt was a CPU version, which worked correctly but was not fast enough for any serious use. CNN with complex architectures are notoriously slow to train, that’s why everyone these days use the GPU. It wasn’t until recently that I got a CUDA version of my code up and running. To keep things simple I didn’t do any fancy optimisation. In fact, I didn’t even use shared memory, mostly due to the way I structured my algorithm. Despite that, it was about 10-11x faster than the CPU version (single thread). But hang on, there’s already an excellent CUDA CNN code on the net, namely cuda-convnet, why bother rolling out my own one? Well, because my GPU is a laptop GTS 360M (circa 2010 laptop), which only supports CUDA compute 1.2. Well below the minimum requirements of cuda-convnet. I could get a new computer but where’s the fun in that 🙂 And also, it’s fun to re-invent the wheel for learning reasons.
Results
As mentioned previously I’m working with the CIFAR-10 dataset, which has 50,000 training images and 10,000 test images. Each image is a tiny 32×32 RGB image. I split the 50,000 training images into 40,000 and 10,000 for training and validation, respectively. The dataset has 10 categories ranging from dogs, cats, cars, planes …
The images were pre-processed by subtracting each image by the average image over the whole training set, to centre the data.
The architecture I used was inspired from cuda-convnet and is
Input – 32×32 image, 3 channels
Layer 1 – 5×5 convolution filter, 32 output channels/features, Rectified Linear Unit neurons
Layer 2 – 2×2 max pool, non-overlapping
Layer 3 – 5×5 convolution filter, 32 output channels/features, Rectified Linear Unit neurons
Layer 4 – 2×2 max pool, non-overlapping
Layer 5 – 5×5 convolution filter, 64 output channels/features, Rectified Linear Unit neurons
Layer 6 – fully connected neural network hidden layer, 64 output units, Rectified Linear Unit neurons
Layer 7 – fully connected neural network hidden layer, 10 output units, linear neurons
Layer 8 – softmax, 10 outputs
I trained using a mini-batch of 128, with a learning rate of 0.001 and momentum of 0.9. At each epoch (one pass through the training data), the data is randomly shuffled. At around the 62th epoch I reduced the learning rate to 0.0001. The weights are updated for each mini-batch processed. Below shows the validation errors vs epoch.
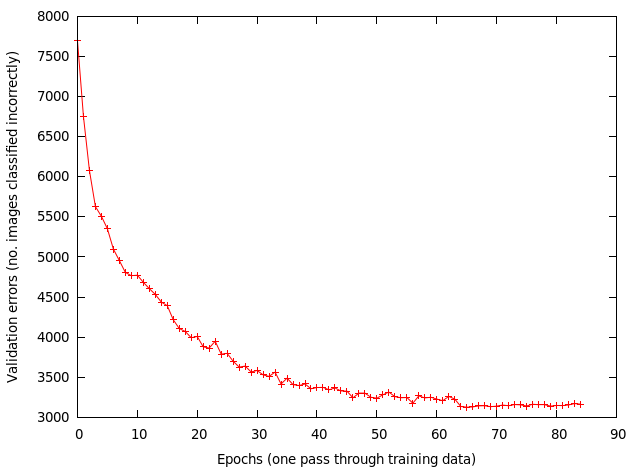
After 85 epochs the results are:
– training error 7995/40000 ~ 20%
– validation error 3156/10000 = 31.56%
– test error 3114/10000 = 31.14%
Results seem okay until I compared them with results reported by cuda-convnet simplest architecture [1] [2]: ~8 epochs (?), 80 seconds, 26% testing error. Where as mine took a few hours and many more epochs, clearly I’m doing something wrong!!! But what? I did a rough back of the envelope calculation and determined that their GPU code runs 33x faster than mine, based on timing values they reported. Which means my CUDA code and hardware sucks badly.
On the plus side I did manage to generate some cool visualisation of the weights for layer 1. These are the convolution filters it learnt. This result is typical of what you will find published in the literature, so I’m confident I’m doing something right.
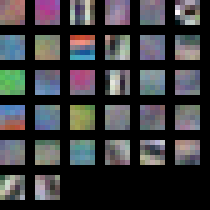
You can see it has learnt some edge and colour filters.
One thing I really want to try at the moment is to get my hands on a newer Nvidia card and see how much speed up I get without doing anything to the code.
I’m not releasing any code yet because it’s very experimental and too ugly to show.
Nghia, you mentioned that you shuffled the data randomly after each epoch. I wonder how much does it benefit the performance. Do you know if Alex’s ConvNet does shuffling as well?
I can’t remember if Alex’s ConvNet does the shuffling but I did it based on the neural network/machine learning classes on Coursera. It’s to meant to minimize overfitting and stop the network from learning a particular sequence of data.
Thanks for your reply.
I’m looking in the convnet code, but I can’t figure out where would this shuffling take place in the code.
Should it be done here:
https://code.google.com/p/cuda-convnet/source/browse/trunk/src/data.cu ?
I can see some randomizing happening here:
https://code.google.com/p/cuda-convnet/source/browse/trunk/src/nvmatrix/nvmatrix.cu
but I’m new to cuda, so I’m not sure what exactly it’s doing…
Thanks,
Michael
I don’t know his code so you’re better off contacting him directly.
a nice talk about convolutional neural networks:
http://techenablement.com/deep-learning-webinar-demonstrates-handwriting-recognition-and-efforts-to-teach-drone-to-fly-down-a-wooded-path/
Do you have the code implemented in Matlab?
No
can you please the difference between working with 3d images using the same convoltuional neural networks…
I’ve never worked with 3D images with a CNN. You’ll have to check the literature on this.
Can you still release the code for the experiment?
I don’t have code for this exact one, but you can use the previous code I released and change the parameters for this particular one.
“At each epoch (one pass through the training data), the data is randomly shuffled.” Did you shuffle the training data or testing data?
If a CNN is trained with a shuffled training data does it make a difference in the accuracy ? If so what do you think the reason behind it is?
I shuffle the training data.
The shuffling is supposedly meant to prevent the network from learning the same sequence of images and reduce over fitting.
Can you teach me run code Cifar 10 in Windows? Thanks
i don’t use Windows so you are better off finding someone who has already done this.
How did you get the weights to visualize like that? I’m getting a test error percent around 25% with a small network, but when I normalize the weights and show them as RGB, I just get noise.
The CNN naturally finds weight with structure in them for images. I didn’t have to do anything special.